(IN PROGRESS) Writing a transformer (almost) from scratch
I’m primarily writing this to consolidate my understanding. The code referred to in this post can be found at my GitHub
Transformers
Transformers model sequences. They have had tremendous success, especially in modelling language. Given a sequence they predict the next token in the sequence. We sample incrementally to further generate more of the sequence.
The task of the transformer is to predict the next token in the sequnce. We will call these predictions logits and each logit is a vector where each entry corresponds to a unique token in the vocabulary.
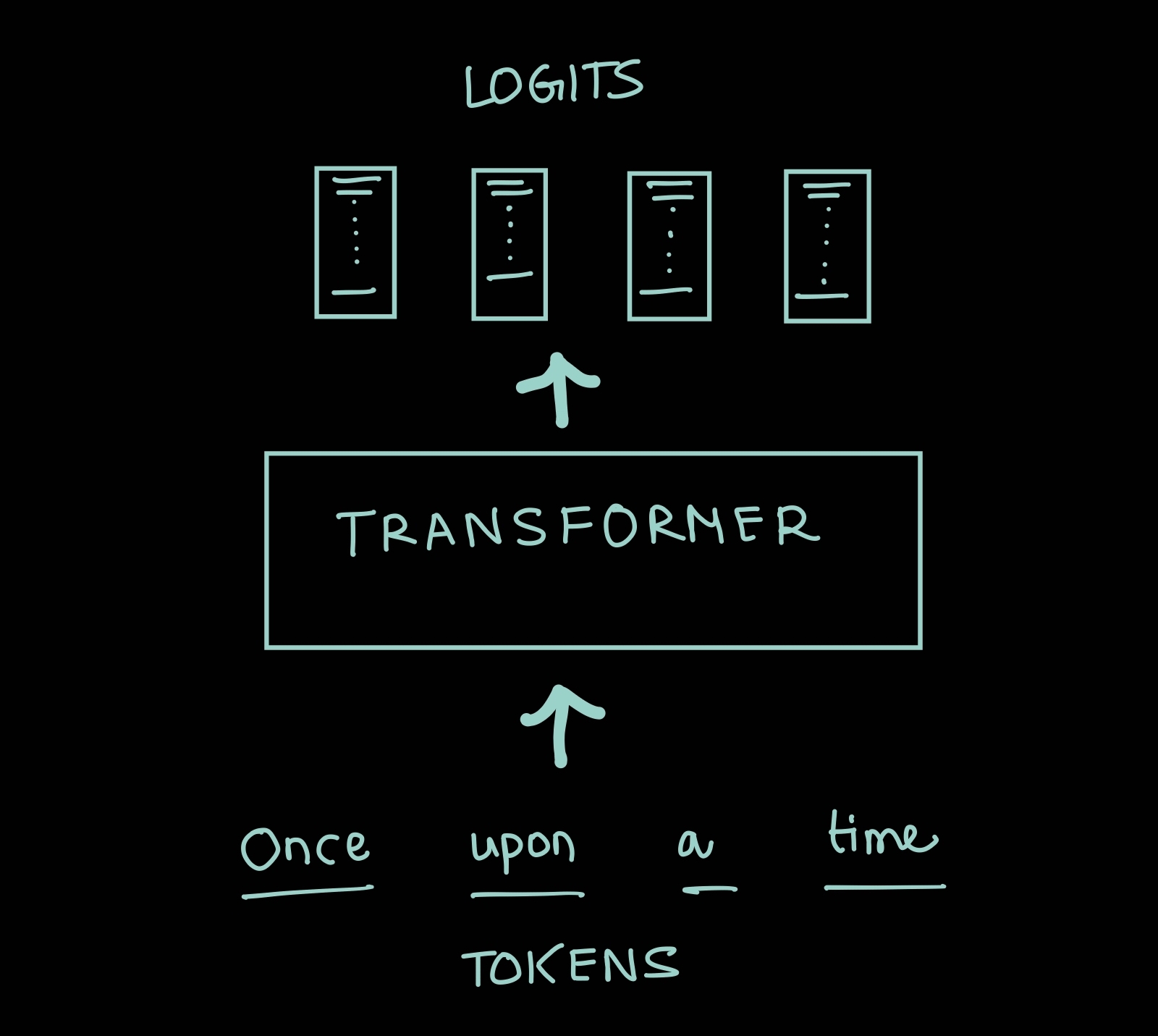
Tokens and Vocabulary
Tokens are the basic units of the sequences we are modelling. The set of all tokens is called vocabulary.
If we were to model English language, we have different choices possible for the vocabulary. One basic idea is to have the set of ASCII characters as our vocabulary. This is a very concise set but it is too simplistic - it doesn’t capture the fact that some sequences of characters more meaningful than the rest. In fact most combinations are meaningless. Another idea would be to use a standard English dictionary but this doesn’t capture punctuation, urls etc.
What really turned out to be successful is Byte-Pair encoding, where we start with ASCII characters as our vocabulary, find the most common pairs, merge and add them as tokens.
In this post, we will use a pre-built tokenizer and focus on the transformer.
Components of a Transformer
Embedding
1
2
3
4
5
6
7
8
9
class Embed(nn.Module):
def __init__(self, cfg: Config):
super().__init__()
self.cfg = cfg
self.W_E = nn.Parameter(t.empty(cfg.d_vocab, cfg.d_model))
nn.init.normal_(self.W_E, std=self.cfg.init_range)
def forward(self, tokens: Int[Tensor, "batch pos"]) -> Float[Tensor, "batch pos d_model"]:
return self.W_E[tokens]
Position Embedding
1
2
3
4
5
6
7
8
9
10
11
12
class PosEmbed(nn.Module):
def __init__(self, cfg: Config):
super().__init__()
self.cfg = cfg
self.W_pos = nn.Parameter(t.empty((cfg.n_ctx, cfg.d_model)))
nn.init.normal_(self.W_pos, std=self.cfg.init_range)
def forward(self, tokens:Int[Tensor, "batch pos"]) ->
Float[Tensor, "batch pos d_model"]:
b, p = tokens.shape
positions = t.arange(0, p).repeat((b, 1))
return self.W_pos[positions]
Layer Norm
1
2
3
4
5
6
7
8
9
10
11
12
13
class LayerNorm(nn.Module):
def __init__(self, cfg:Config):
super().__init__()
self.eps = cfg.layer_norm_eps
self.w = nn.Parameter(t.ones(cfg.d_model))
self.b = nn.Parameter(t.zeros(cfg.d_model))
def forward(self, residual: Float[Tensor, "batch pos d_model"]) ->
Float[Tensor, "batch pos d_model"]:
mean = t.mean(residual, dim=-1, keepdim=True)
variance = t.var(residual, dim=-1, keepdim=True, unbiased=False)
out = (residual - mean) / ((variance + self.eps) ** (0.5))
return out * self.w + self.b
Self-Attention
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
class Attention(nn.Module):
EPSILON: Float[Tensor, ""]
def __init__(self, cfg: Config):
super().__init__()
self.cfg = cfg
n, e, h = cfg.n_heads, cfg.d_model, cfg.d_head
self.W_Q = nn.Parameter(t.empty((n, e, h)))
self.b_Q = nn.Parameter(t.zeros((n, h)))
self.W_K = nn.Parameter(t.empty((n, e, h)))
self.b_K = nn.Parameter(t.zeros((n, h)))
self.W_V = nn.Parameter(t.empty((n, e, h)))
self.b_V = nn.Parameter(t.zeros((n, h)))
self.W_O = nn.Parameter(t.empty(n, h, e))
self.b_O = nn.Parameter(t.zeros(e))
nn.init.normal_(self.W_Q, std=self.cfg.init_range)
nn.init.normal_(self.W_K, std=self.cfg.init_range)
nn.init.normal_(self.W_V, std=self.cfg.init_range)
nn.init.normal_(self.W_O, std=self.cfg.init_range)
self.register_buffer("EPSILON", t.tensor(-1e5, dtype=t.float32, device=device))
def forward(self, normalized_resid_pre: Float[Tensor, "batch pos d_model"]) ->
Float[Tensor, "batch pos d_model"]:
# b - num batches, s - seq len, e - d_model, n - n_heads, h - d_heads
keys = einops.einsum(
normalized_resid_pre, self.W_K,
"b s e, n e h -> b s n h"
) + self.b_K
queries = einops.einsum(
normalized_resid_pre, self.W_Q,
"b s e, n e h -> b s n h"
) + self.b_Q
attn_scores = einops.einsum(
queries, keys,
"b s1 n h, b s2 n h -> b n s1 s2"
)
attn_scores /= self.cfg.d_head ** 0.5
attn_scores = self.apply_causal_mask(attn_scores)
attn_probs = attn_scores.softmax(dim=-1)
values = einops.einsum(
normalized_resid_pre, self.W_V,
"b s e, n e h -> b s n h"
) + self.b_V
z = einops.einsum(
attn_probs, values,
"b n s1 s2, b s2 n h -> b s1 n h"
)
result = einops.einsum(
z, self.W_O,
"b s n h, n h e -> b s n e"
)
attn_out = einops.reduce(
result,
"b s n e -> b s e", 'sum'
) + self.b_O
return attn_out
def apply_causal_mask(self, attn_scores: Float[Tensor, "batch n_heads query_pos key_pos"]) ->
Float[Tensor, "batch n_heads query_pos key_pos"]:
sq, sk = attn_scores.shape[-2], attn_scores.shape[-1]
ones = t.ones(sq, sk, device=attn_scores.device)
mask = t.triu(ones, diagonal=1).bool()
attn_scores.masked_fill_(mask, self.EPSILON)
return attn_scores
Multi Layer Perceptron
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class MLP(nn.Module):
def __init__(self, cfg: Config):
super().__init__()
self.cfg = cfg
self.W_in = nn.Parameter(t.empty((cfg.d_model, cfg.d_mlp)))
self.W_out = nn.Parameter(t.empty((cfg.d_mlp, cfg.d_model)))
self.b_in = nn.Parameter(t.zeros((cfg.d_mlp)))
self.b_out = nn.Parameter(t.zeros((cfg.d_model)))
nn.init.normal_(self.W_in, std=self.cfg.init_range)
nn.init.normal_(self.W_out, std=self.cfg.init_range)
def forward(
self, normalized_resid_mid: Float[Tensor, "batch posn d_model"]
) -> Float[Tensor, "batch posn d_model"]:
out = einops.einsum(
normalized_resid_mid, self.W_in,
"batch posn d_model, d_model d_mlp -> batch posn d_mlp"
) + self.b_in
out = gelu_new(out)
out = einops.einsum(
out, self.W_out,
"batch posn d_mlp, d_mlp d_model -> batch posn d_model"
) + self.b_out
return out
Transformer Block
1
2
3
4
5
6
7
8
9
10
11
12
13
class TransformerBlock(nn.Module):
def __init__(self, cfg: Config):
super().__init__()
self.cfg = cfg
self.ln1 = LayerNorm(cfg)
self.attn = Attention(cfg)
self.ln2 = LayerNorm(cfg)
self.mlp = MLP(cfg)
def forward(self, resid_pre: Float[Tensor, "batch pos d_model"]) ->
Float[Tensor, "batch pos d_model"]:
x = self.attn(self.ln1(resid_pre)) + resid_pre
return x + self.mlp(self.ln2(x))
Unembedding
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class Unembed(nn.Module):
def __init__(self, cfg: Config):
super().__init__()
self.cfg = cfg
self.W_U = nn.Parameter(t.empty((cfg.d_model, cfg.d_vocab)))
nn.init.normal_(self.W_U, std=self.cfg.init_range)
self.b_U = nn.Parameter(t.zeros((cfg.d_vocab), requires_grad=False))
def forward(self, normalized_resid_final: Float[Tensor, "batch pos d_model"]) ->
Float[Tensor, "batch pos d_vocab"]:
out = einops.einsum(
normalized_resid_final, self.W_U,
"batch pos d_model, d_model d_vocab -> batch pos d_vocab"
) + self.b_U
return out
Comments powered by Disqus.